\title {The Developing Mind \\ The Mindreading Puzzle: a Solution?}
\maketitle

The Mindreading Puzzle: a Solution?
[email protected]
\def \ititle {The Mindreading Puzzle: a Solution?}
\begin{center}
{\Large
\textbf{\ititle}
}
\iemail %
\end{center}
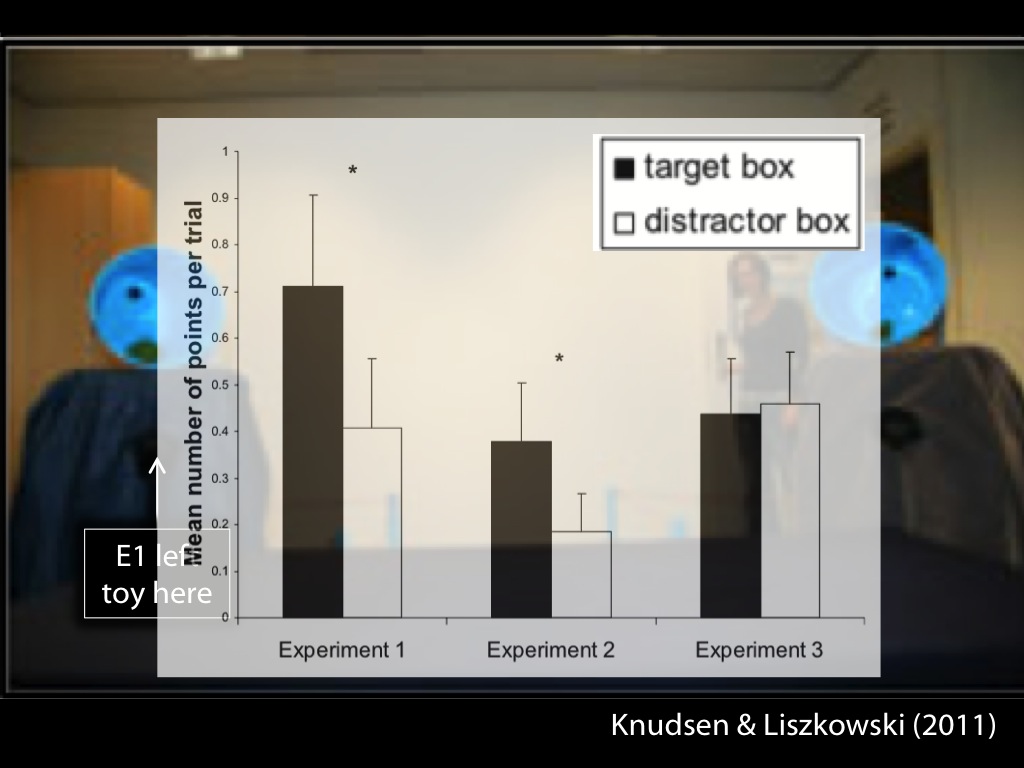
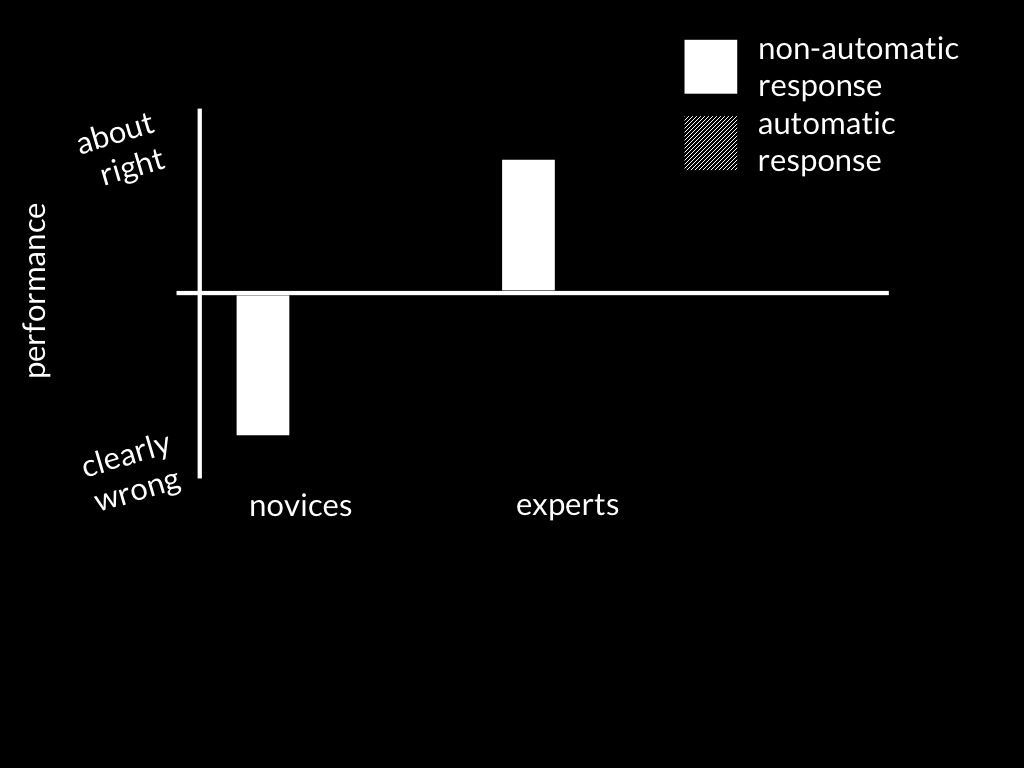
Schneider et al (2014, figure 1)
One way to show that mindreading is automatic is to give subjects a task which does not require tracking beliefs and then to compare their performance in two scenarios:
a scenario where someone else has a false belief, and a scenario in which someone else has a true belief.
If mindreading occurs automatically, performance should not vary between the two scenarios because others’ beliefs are always irrelevant to the subjects’ task and motivations.
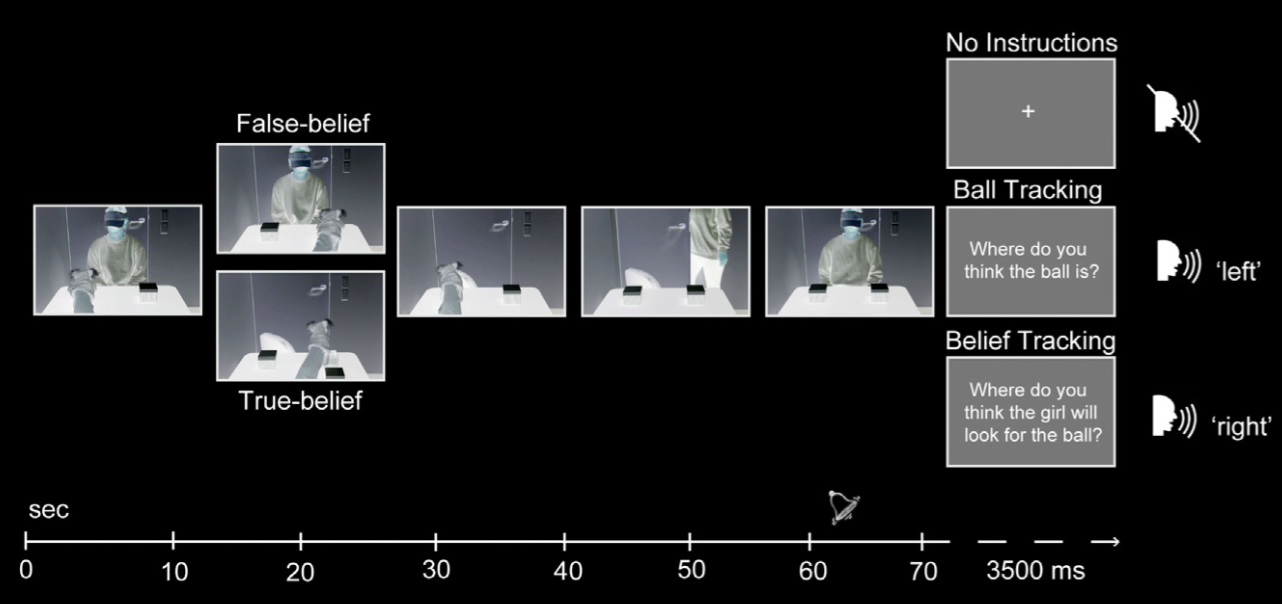
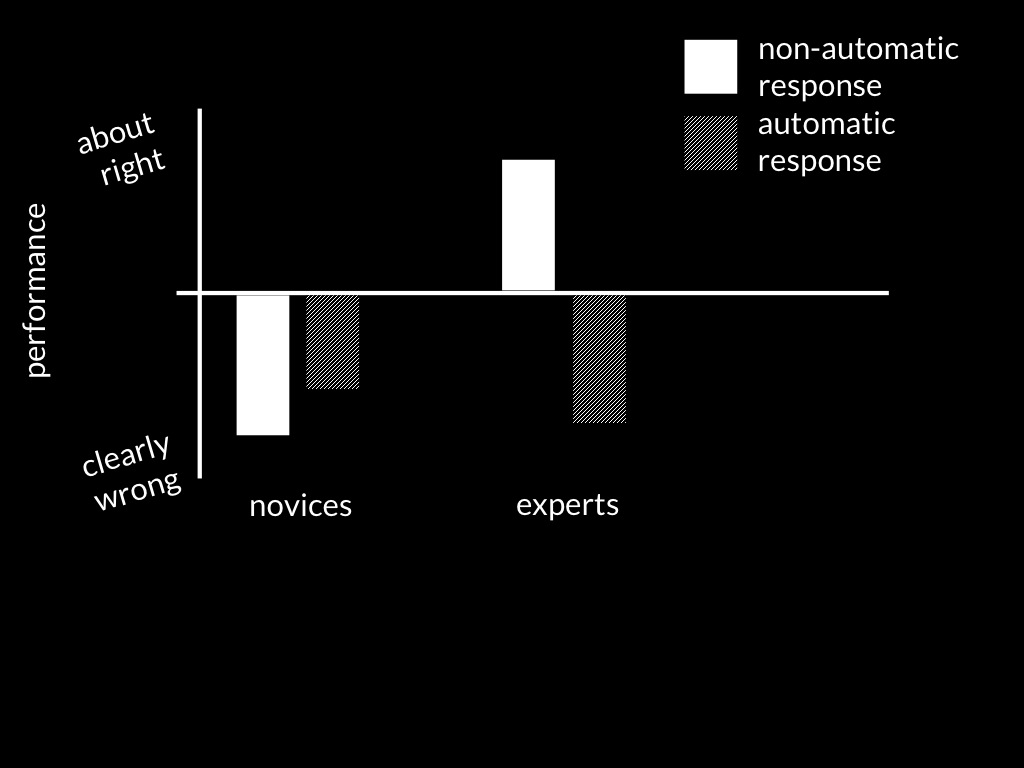
Schneider et al (2014, figure 3)
\citet{Schneider:2011fk} did just this.
They showed their participants a series of videos and instructed them to detect when a figure waved or, in a second experiment, to discriminate between high and low tones as quickly as possible.
Performing these tasks did not require tracking anyone’s beliefs, and the participants did not report mindreading when asked afterwards.
on experiment 1: ‘Participants never reported belief tracking when questioned in an open format after the experiment (“What do you think this experiment was about?”). Furthermore, this verbal debriefing about the experiment’s purpose never triggered participants to indicate that they followed the actor’s belief state’ \citep[p.~2]{Schneider:2011fk}
Nevertheless, participants’ eye movements indicated that they were tracking the beliefs of a person who happened to be in the videos.
In a further study, \citet{schneider:2014_task} raised the stakes by giving participants a task that would be harder to perform if they were tracking another’s beliefs.
So now tracking another’s beliefs is not only irrelevant to performing the tasks: it may actually hinder performance.
Despite this, they found evidence in adults’ looking times that they were tracking another’s false beliefs.
This indicates that ‘subjects … track the mental states of others even when they have instructions to complete a task that is incongruent with this operation’ \citep[p.~46]{schneider:2014_task} and so provides evidence for automaticity.%
\footnote{%
% quote is necessary to qualify in the light of their interpretation; difference between looking at end (task-dependent) and at an earlier phase (task-independent)?
%\citet[p.~46]{schneider:2014_task}: ‘we have demonstrated here that subjects implicitly track the mental states of others even when they have instructions to complete a task that is incongruent with this operation. These results provide support for the hypothesis that there exists a ToM mechanism that can operate implicitly to extract belief like states of others (Apperly & Butterfill, 2009) that is immune to top-down task settings.’
It is hard to completely rule out the possibility that belief tracking is merely spontaneous rather than automatic.
I take the fact that belief tracking occurs despite plausibly making subjects’ tasks harder to perform to indicate automaticity over spontaneity.
If non-automatic belief tracking typically involves awareness of belief tracking, then the fact that subjects did not mention belief tracking when asked after the experiment about its purpose and what they were doing in it further supports the claim that belief tracking was automatic.
}
Further evidence that mindreading can occur in adults even when counterproductive has been provided by \citet{kovacs_social_2010}, who showed that another’s irrelevant beliefs about the location of an object can affect how quickly people can detect the object’s presence,
and by \citet{Wel:2013uq}, who showed that the same can influence the paths people take to reach an object.
Taken together, this is compelling evidence that mindreading in adult humans sometimes involves automatic processes only.
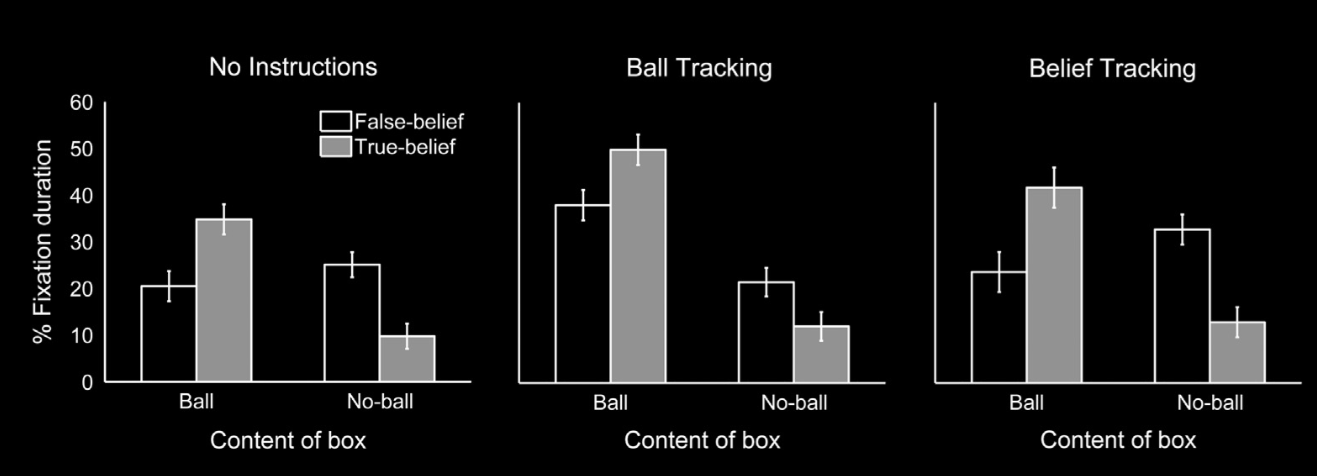
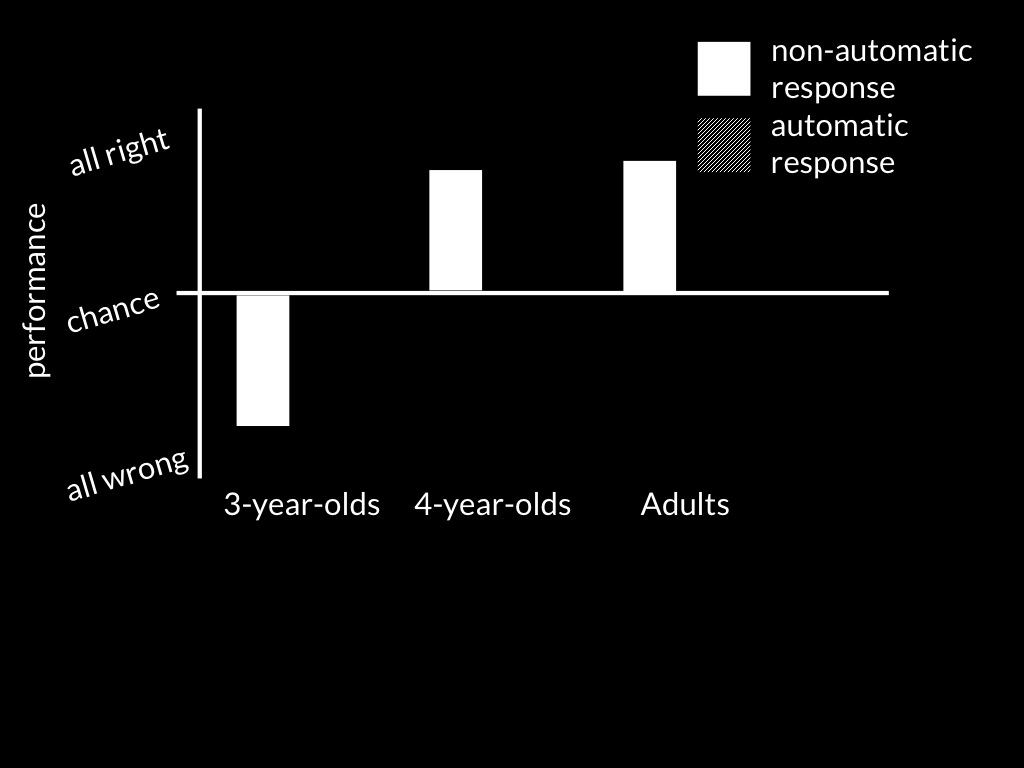
Back & Apperly (2010, fig 1, part)
This is the data for answers that required a ‘yes’ response.
So does all mindreading in adult humans involve only processes which are automatic?
No: it turns out that verbal responses in false belief tasks that are A-tasks are not typically a consequence of automatic belief tracking.
To show this, \citet{back:2010_apperly} instructed people to watch videos in which someone acquires a belief, either true or false, and then, after the video, asked them an unexpected question about the protagonist’s belief \citep[see also][]{apperly:2006_belief}.
They measured how long people took to answer this question.
Starting with the hypothesis that answering a question about belief involves automatic mindreading only,
they reasoned that the mindreading necessary to answer a question about belief will have occurred before the question is even asked.
Accordingly there should be no delay in answering an unexpected question about belief—or, at least, no more delay than in answering unexpected questions about any other facts that are automatically tracked.
But they found that people were slower to answer unexpected questions about belief than predicted.
Importantly this was not due to any difficulty with questions about belief as such: when such questions were expected, they were answered just as quickly as other, non-belief questions.
It seems that, when asked an unexpected question about another’s belief, people typically need time to work out what the other believes.
We must therefore reject the hypothesis that answering a question about belief involves automatic mindreading only.%
\footnote{%
\citet[ms~p.~9]{carruthers:2015_mindreading} objects (following \citealp{cohen:2009_encoding}) that these experiments are ‘not really about encoding belief but recalling it.’
Note that this objection is already answered by \citet[p.~56]{back:2010_apperly}.
}
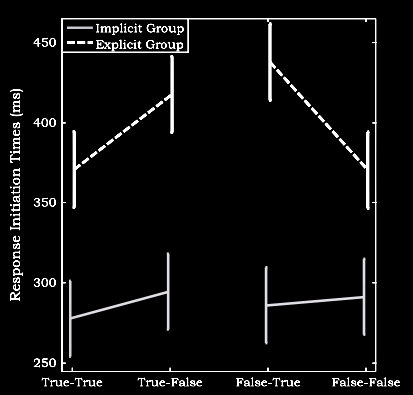
\citep[p.\ 132]{Wel:2013uq}:
‘In support of a more rule-based and controlled system, we found that response initiation times
changed as a function of the congruency of the participant’s and the agent’s belief in the
explicit group only. Thus, when participants had to track both beliefs, they slowed down
their responses when there was a belief conflict versus when there was not. The observation
that this result only occurred for the explicit group provides evidence for a controlled system.’
van der Wel et al (2014, figure 3)

One inconsistent response.
Might just be that automatic responses is a more sensitve measure ...
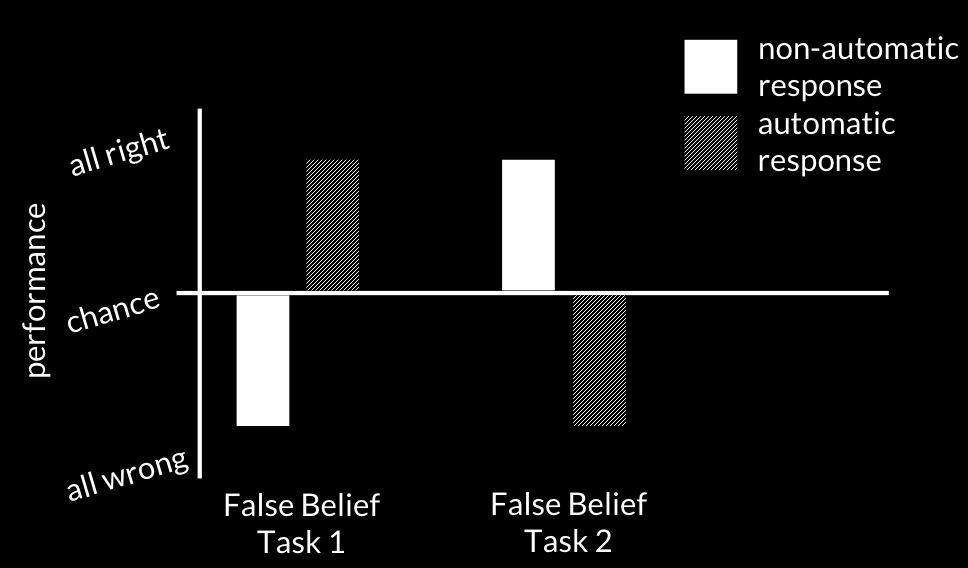
Here the idea is that, on the first task, one measure indicates that the subjects
predict an action that would be rational given a false belief whereas the other measure
indicates that the same subejcts predict a different action, one that would not be rational
given the false belief.
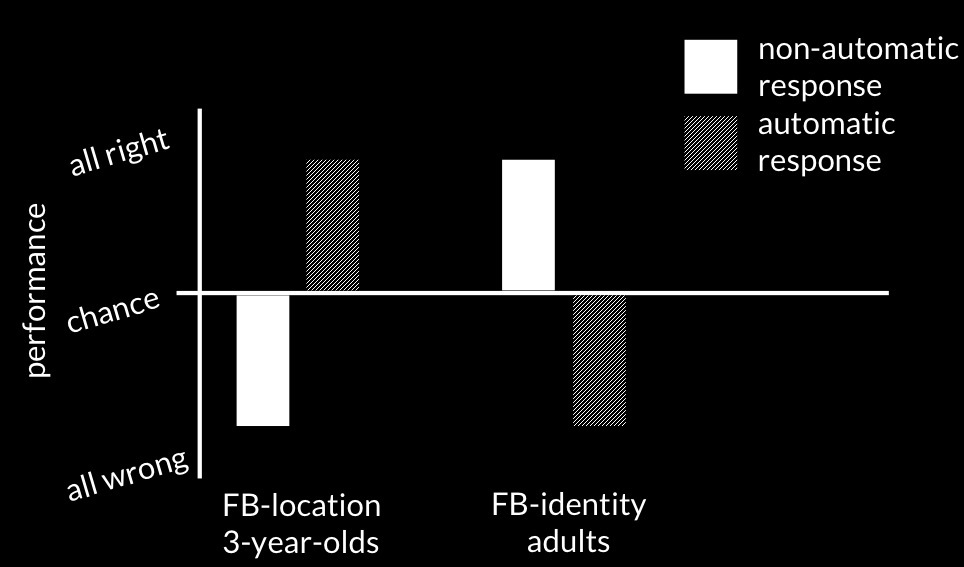
Switch from two tasks to 2 ages and location vs identity.
How do mindreadersmodel minds?
The notion of model complements that of system.
The idea is going to be that different belief-tracking systems rely on different models of the mental.
But I'm getting ahead.
Let me start with a simple question.
How do mindreaders model minds?


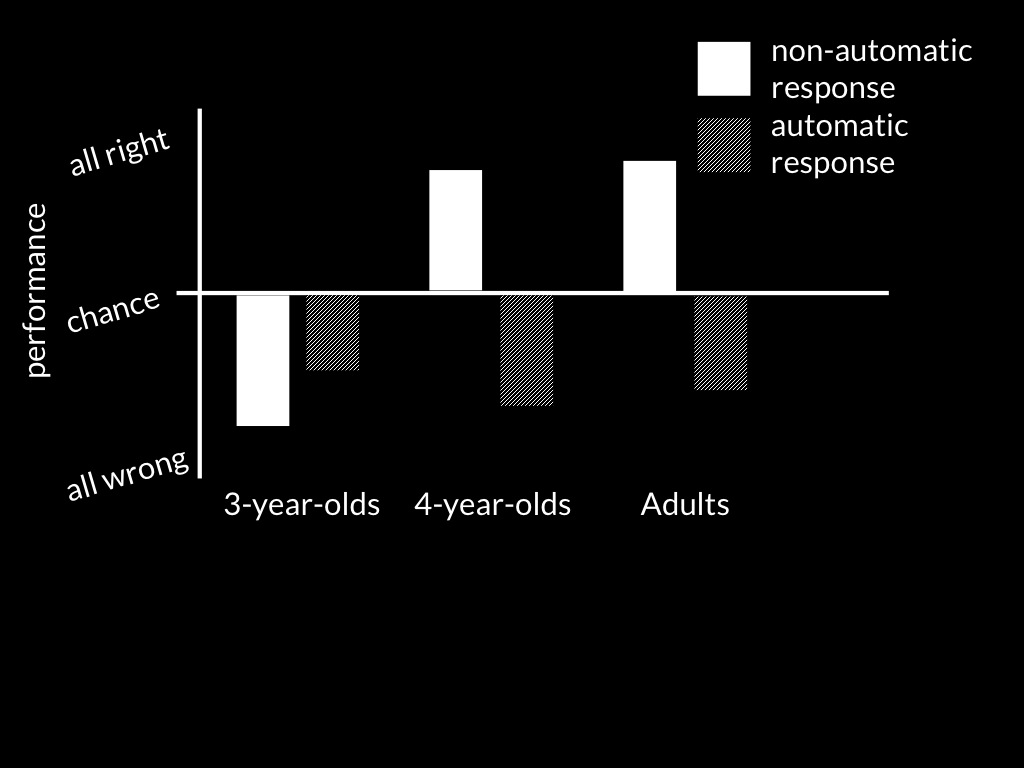
False-Belief:Identity task
adapted from Low & Watts (2013); Low et al (2014); Wang et al (2015)
There is some evidence that this prediction is correct.
Jason Low and his collegaues set out to test it.
They have now published three
different papers showing such limits; and Hannes Rakoczy and others
have more work in progress on this.
Collapsing several experiements using different approaches,
the basic pattern of their findings is this ...
Take non-automatic responses first; in this case, communicative responses.
When you do a false-belief-identity task, you see the pattern you also
find for false-belief-locations tasks.
But things look different when you measure non-automatic responses ...
False-Belief:Identity task
adapted from Low & Watts (2013); Low et al (2014); Wang et al (2015)
The non-automatic responses all show the signature limit of minimal
models of the mental.
This is evidence for the hypothesis that
Some automatic belief-tracking systems rely on minimal models of the mental.
I also hear that quite a few scientists have pilot data that speaks
against this signature limit.
One particular task for future research will be to examine whether other
automatic responses to scenarios involving false beliefs about identity,
such as response times and movement trajectories, are also subject
to this signature limit.
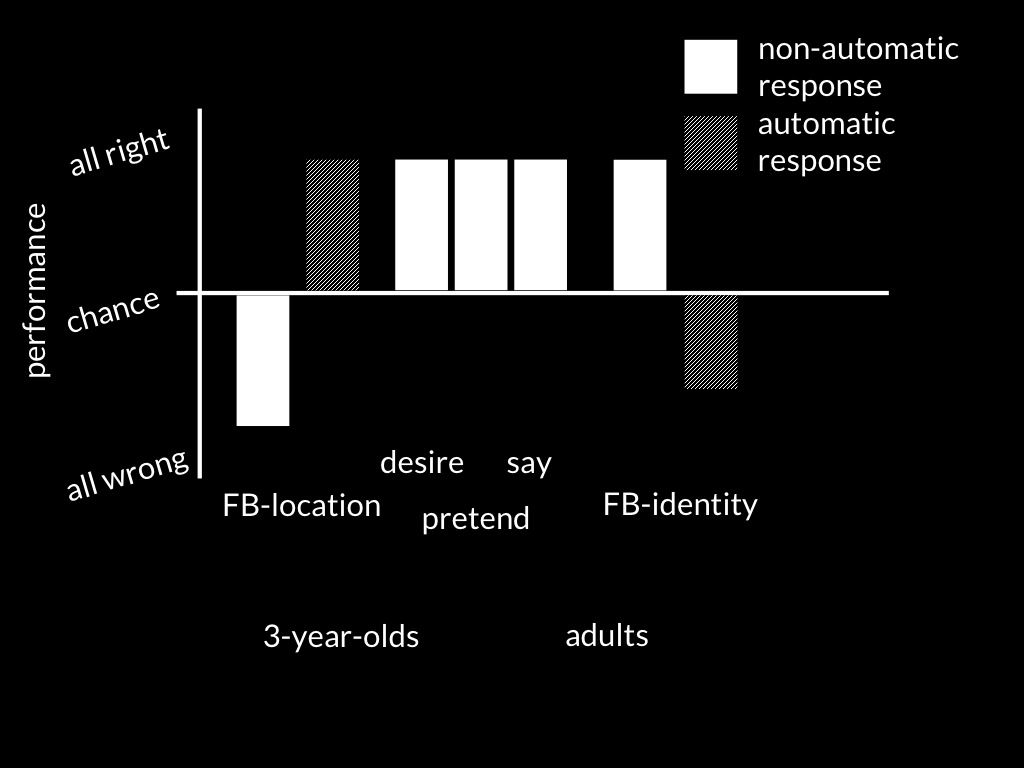
3-year-olds’ performance is not simply the result of performance factors.
After all, they succeed on structurally similar tasks about
pretence, saying or desiring.
Further, changing the EF demands of a FB task doesn’t affect performance,
and, conversely, nor do differences between cultures in EF affect FB
performance.
Consistently with this, success on FB predicts later social competence
independently of EF.
But then what about the developmental relation between EF and FB performance?
It's emergence not performance (?).

[This is here in case I have to explain Low et al’s identity task]
This is what you as subject see.
Actually you can't see this so well, let me make it bigger.





This is how the experiment progresses.
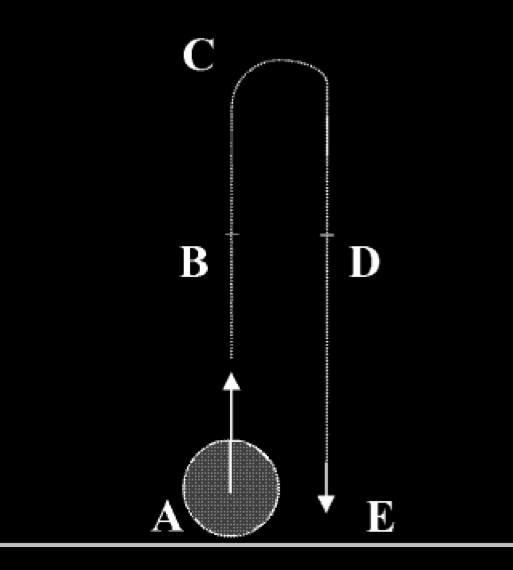
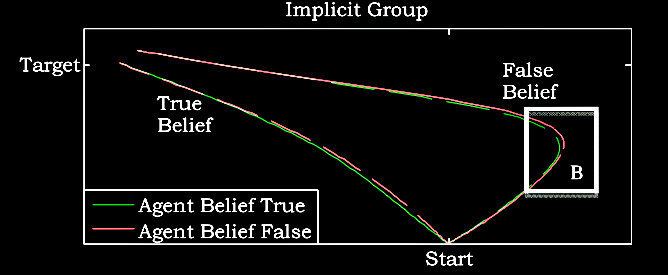
van der Wel et al (2014, figure 1)
Just look at the 'True Belief' lines (the effect can also be found when your belief
turns out to be false, but I'm not worried about that here.)
Do you see the area under the curve?
When you are moving the mouse,
the protagonist's false belief is pulling you away from the actual location
and towards the location she believes this object to be in!
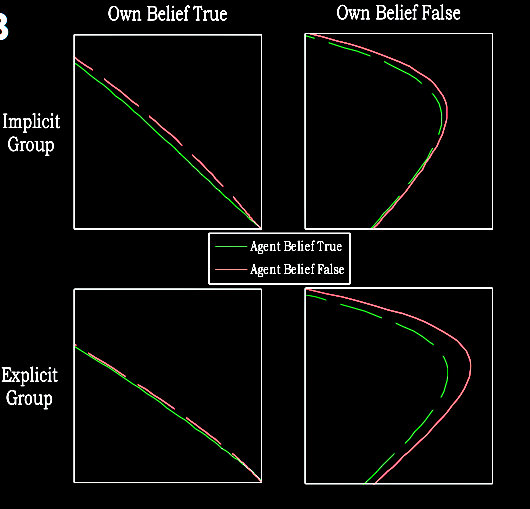
van der Wel et al (2014, figure 2)
Here's a zoomed in view. We're only interested in the top left box (implicit condition,
participant has true belief).
To repeat,
When you are moving the mouse,
the protagonist's false belief is pulling you away from the actual location
and towards the location she believes this object to be in!
van der Wel et al (2014, figure 2)
\citep[p.\ 132]{Wel:2013uq}:
‘In support of a more rule-based and controlled system, we found that response initiation times
changed as a function of the congruency of the participant’s and the agent’s belief in the
explicit group only. Thus, when participants had to track both beliefs, they slowed down
their responses when there was a belief conflict versus when there was not. The observation
that this result only occurred for the explicit group provides evidence for a controlled system.’
van der Wel et al (2014, figure 3)